Karan Desai

I am a founding member at World Labs. I curate petabyte-scale datasets and train large diffusion models that power Marble, our first product allowing users to generate, edit, and export 3D worlds. My data work has also shaped the pre-training strategy of RTFM, our research on Real-Time Frame Models.
I finished my PhD in Computer Science at the University of Michigan in May 2024, advised by Justin Johnson. My PhD work centered on visual representation learning, vision-language models, and image segmentation. I am glad to have enjoyed working on these topics in academia back then, before they became mainstream in the current wave of Gen AI products since the virality of ChatGPT release in 2022. My thesis, titled Language Supervision for Computer Vision, is available publicly.
These days, my favorite pockets of time at work and in personal projects are with data. I enjoy the process of iteratively growing web-scale datasets, increasing their quality density by hand-designing data transforms to filter or select samples to better train generative models. I like finding simple ways to source data, be it from the internet or by manually recording videos. I like vibe coding web interfaces to manually hand-annotate samples or to simply eyeball thousands of images. During and before my PhD, I worked on three dataset projects: nocaps, RedCaps, and COCO-ReM. For the last one, I manually inspected and refined nearly 40,000 segmentation masks to ensure high quality. Those few days were very exhausting, yet very satisfying.
In my free time, I love rickrolling all my friends.Selected Blogs
World Labs' first product to generate 3D worlds from text, images, videos, and 3D layouts. Users can edit and export as Gaussian splats, meshes, and videos.
Research work on generating video in real-time based on user interactions, treating sets of posed images as spatial memory for conditioning.
Selected Publications

Shweta Singh, Aayan Yadav, Jitesh Jain, Humphrey Shi, Justin Johnson, Karan Desai
ECCV 2024 paper bibtex code website
New evaluation dataset and training dataset to study image segmentation models. Our dataset rectifies the inconsistencies in COCO dataset -- imprecise mask boundaries and missing non-exhaustive annotations.
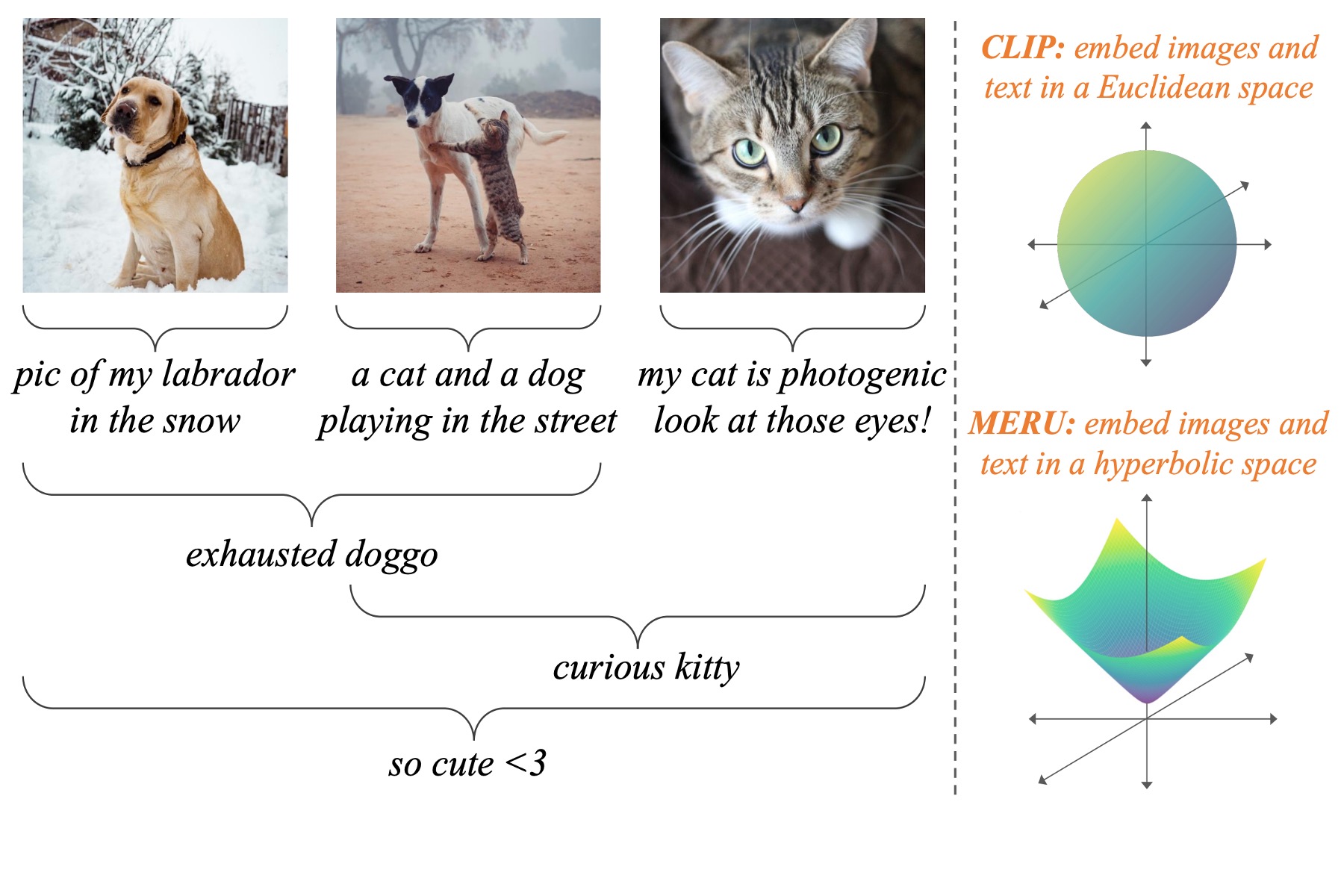
Karan Desai, Maximilian Nickel, Tanmay Rajpurohit, Justin Johnson, Ramakrishna Vedantam
ICML 2023 paper bibtex code
Images and text can be naturally organized into a hierarchy of concepts. Hyperbolic manifolds can embed hierarchies better than flat Euclidean spaces, so we train models that yield hyperbolic image-text representations.
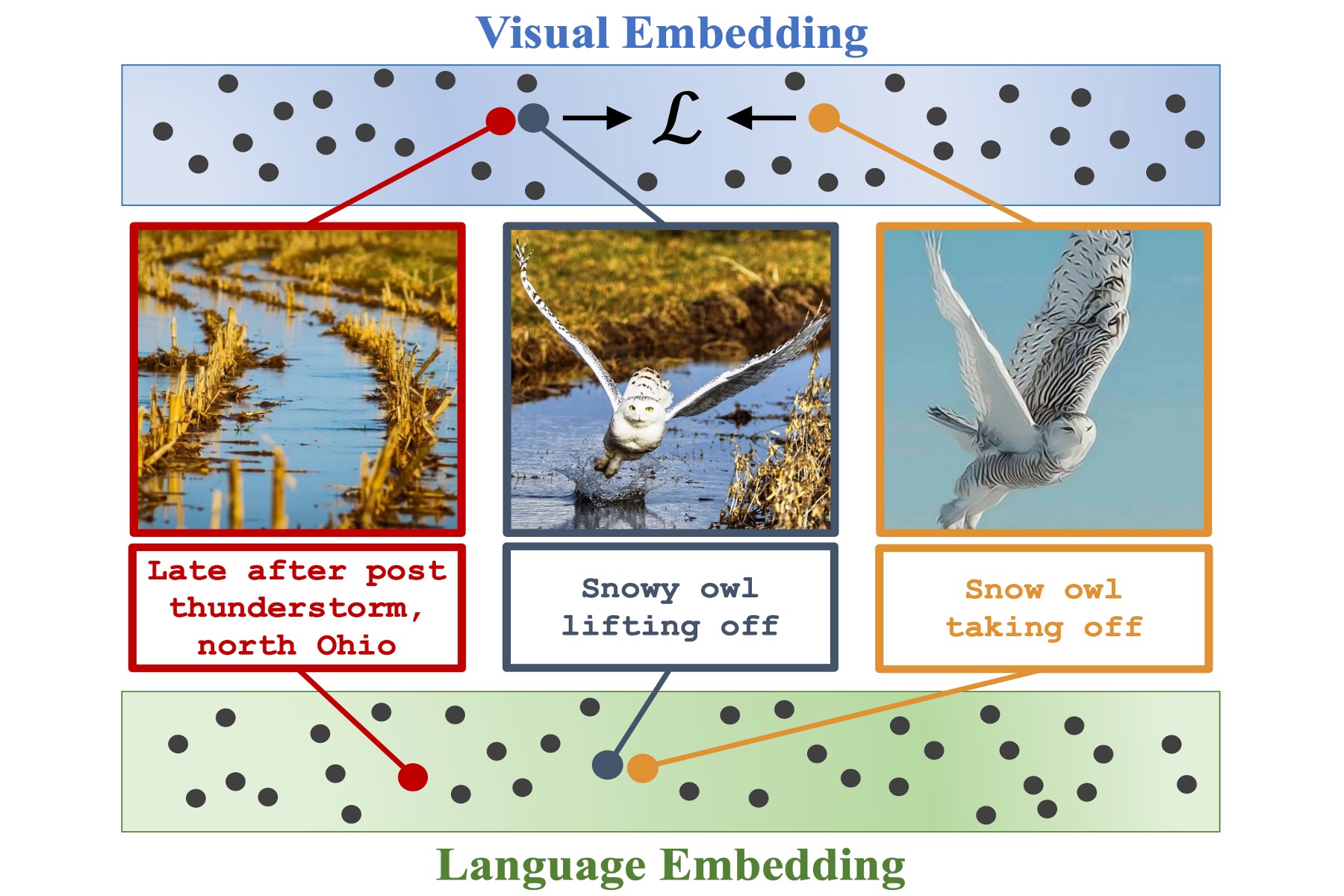
Mohamed El Banani, Karan Desai, Justin Johnson
CVPR 2023 paper bibtex code
Instead of using augmentations to create positive pairs for contrastive learning, use captions to find semantically similar images. Language abstracts away visual variation.

Karan Desai, Gaurav Kaul, Zubin Aysola, Justin Johnson
NeurIPS 2021 (Datasets and Benchmarks) paper bibtex code website
Reddit is a goldmine of naturally paired images and captions. We collect 12M pairs from curated subreddits — high quality data with minimal filtering for representation learning and image captioning.

Ramprasaath R. Selvaraju*, Karan Desai*, Justin Johnson, Nikhil Naik
CVPR 2021 paper bibtex code blog
Self-supervised learning works great on ImageNet's iconic single-object images, but struggles with busy scenes. Teaching the model to localize objects via attention fixes this.
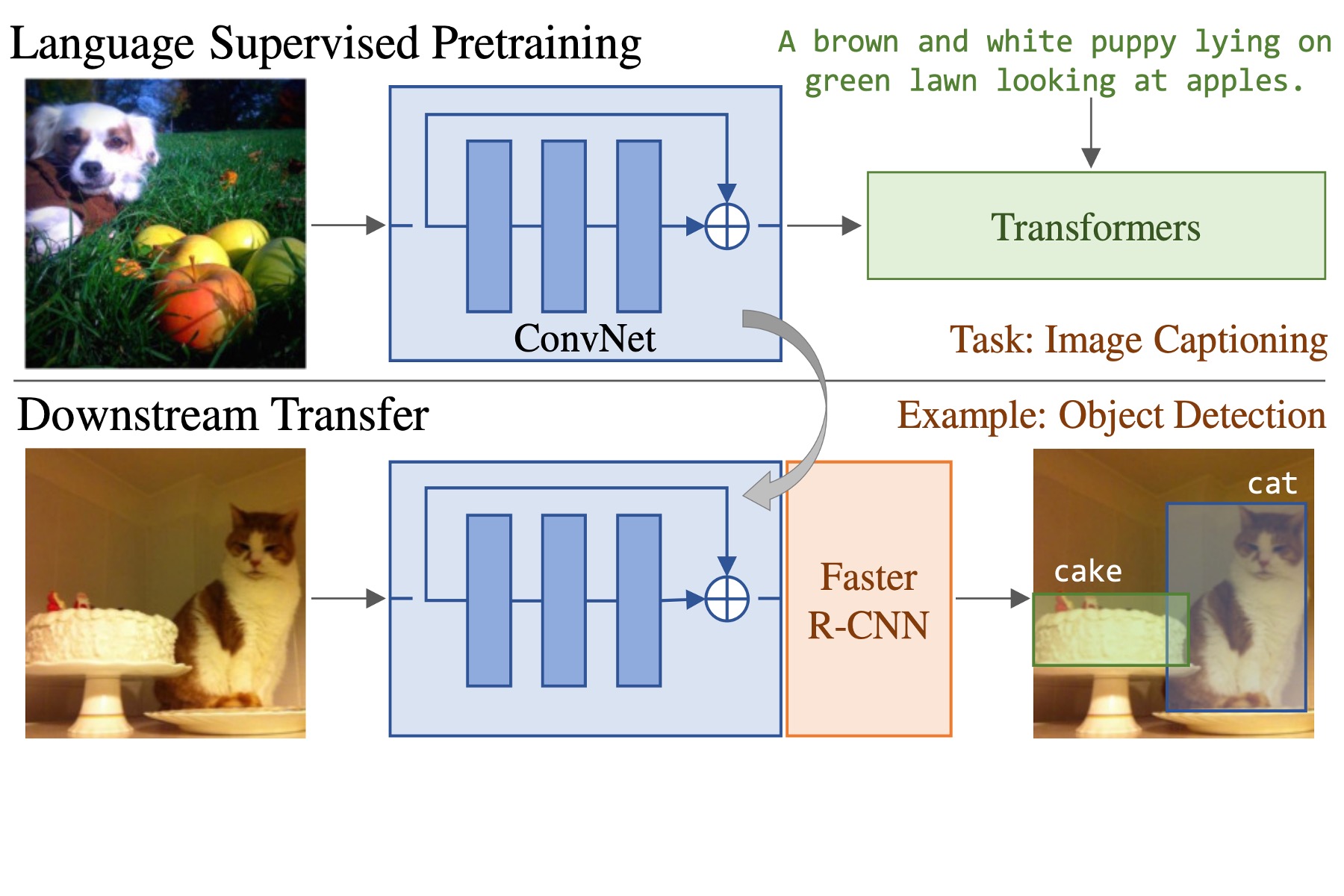
Karan Desai and Justin Johnson
CVPR 2021 paper bibtex code website video
We train image captioning models, then transfer their visual backbone to downstream recognition tasks. Captions provide richer supervision than class labels, matching ImageNet pretraining with 10x fewer images.
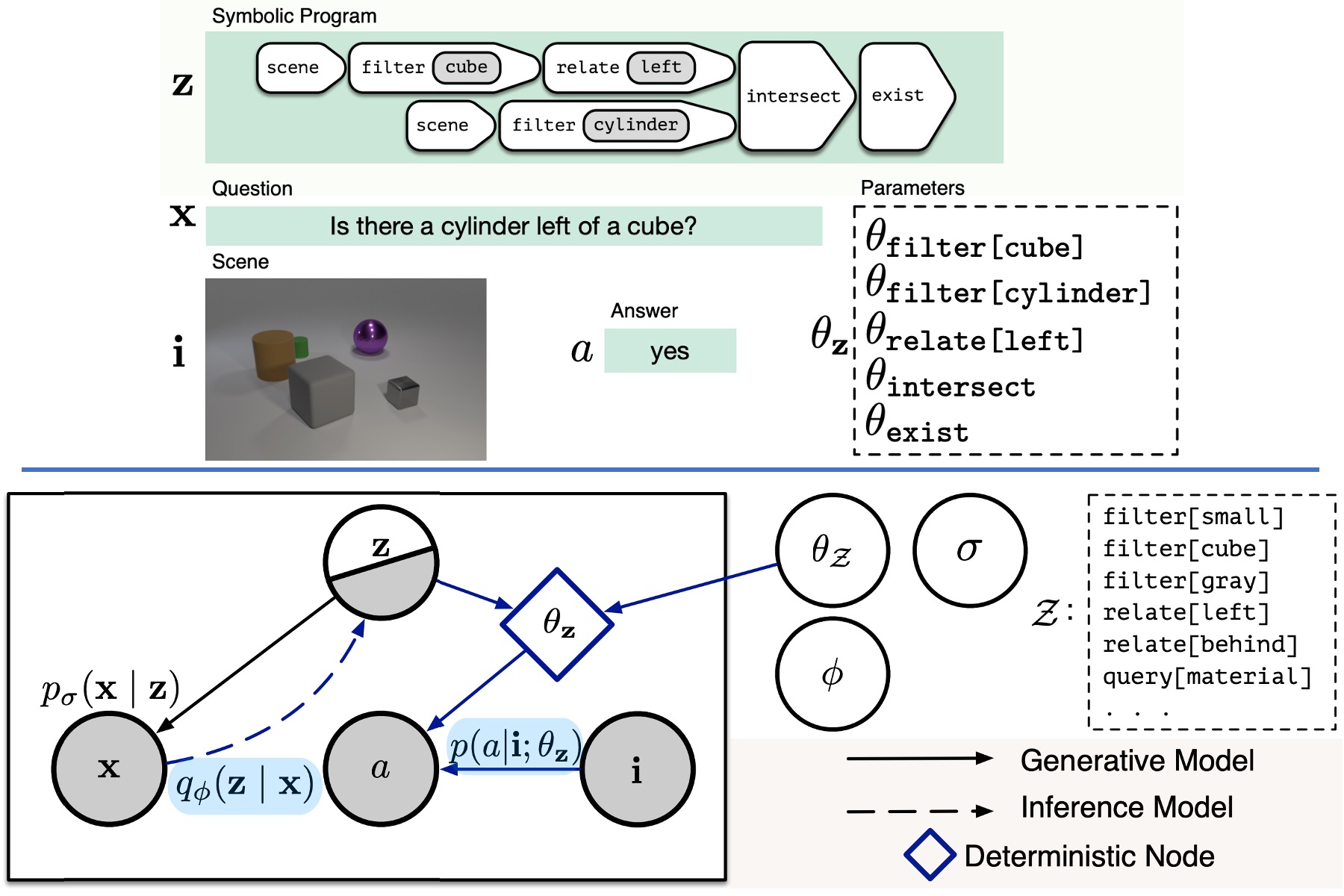
Ramakrishna Vedantam, Karan Desai, Stefan Lee, Marcus Rohrbach, Dhruv Batra, Devi Parikh
ICML 2019 paper bibtex code website
For visual question answering, we treat the reasoning program as a latent variable. This makes the model more interpretable and lets you ask "what program would have given this answer?"

Harsh Agrawal*, Karan Desai*, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, Peter Anderson
ICCV 2019 paper bibtex code website
Can captioning models describe objects they've never seen captions for? This benchmark tests generalization to 400+ novel object classes using detection data as a bridge.
First Projects
I managed to preserve my ‘firsts’ from back in 2015 on Github, and I try to keep them functional for as long as I can. These are my humble beginnings.

My first neural network using numpy, a multi layer perceptron classifier for MNIST. Back then, this repo made to the Github trending charts for almost two weeks. Simpler times.

My first github repository, snake game implemented in JavaScript. The game is still functional and hosted on Github pages.